Task01 西瓜书概览
主要 follw 教程:https://datawhale.feishu.cn/docs/doccndJC2sbSfdziNcahCYCx70W#
只记录一些印象深刻的基本概念,以及自己认为重要的点
第一章:
1、“样本空间”:属性(特征)张成的空间,也叫样本空间。所有特征取值组合的集合。
2、“标记空间”:样本 label 的集合。
3、学习任务可大致分为两大类:监督学习和无监督学习,分类和回归是前者的代表,聚类是后者的代表。
4、通常对样本的假设是:样本空间中的全体样本服从某个未知分布 $\mathcal{D} $ ,我们获得的每个样本都是独立地从这个分布上采样获得的,即独立同分布。
5、归纳(induction):从特殊到一般的泛化(generalization)过程。
6、演绎(deduction):从特殊到一般的特化(specialization)过程。
7、我们可以把学习过程看作一个在所有假设(hypothesis)组成的空间中进行搜索的过程,搜索目标是找到与训练集”匹配“(fit)的假设。
model.fit(train),原来是根据这样的定义来的。
8、归纳偏好(inductive bias):机器学习算法在学习过程中对某种类型假设的偏好。归纳偏好可看作学习算法自身在一个可能很庞大的假设空间中对假设进行选择的启发式或“价值观”。例如“奥卡姆剃刀”。归纳偏好对应了学习算法本身所作出的关于“什么样的模型更好”的假设。
9、NFL定理的理解:https://zhuanlan.zhihu.com/p/11312671
第二章:
1、精度(accuracy,acc)=分类正确的样本数占样本总数的比例;误差(error)=实际预测输出与样本的真实输出之间的差异。
2、从采样(sampling)的角度来看待数据集的划分过程,则保留类别比例的采样方式通常称为“分层采样”(stratified sampling)。
3、p次k折交叉验证法。p次:减少了划分k折时带来的误差,k折:充分利用训练集。
4、留一法(Leave-One-Out)是交叉验证法的特例,测试集数量为1。
5、自助法(bootstrapping),即有放回采样,在数据集较小时很有用,也适合集成学习,但是改变了初始数据集的分布,会引入估计偏差,所以当数据量足够时,建议交叉验证法。
6、给定包含m个样本的数据集D,在模型评估与选择过程中由于需要留出一部分数据进行评估测试,事实上我们只使用了一部分数据训练模型。因此在模型选择完成后,学习算法和参数配置已选定,此时应该用数据集D重新训练模型。这个模型在训练过程中使用了所有m个样本,这才是我们最终提交给用户的模型。
k折交叉验证每个单独模型训练都没有使用全量数据,只用来寻找模型的最佳超参数,确定完超参数以后再全量训练一次得到最终模型。
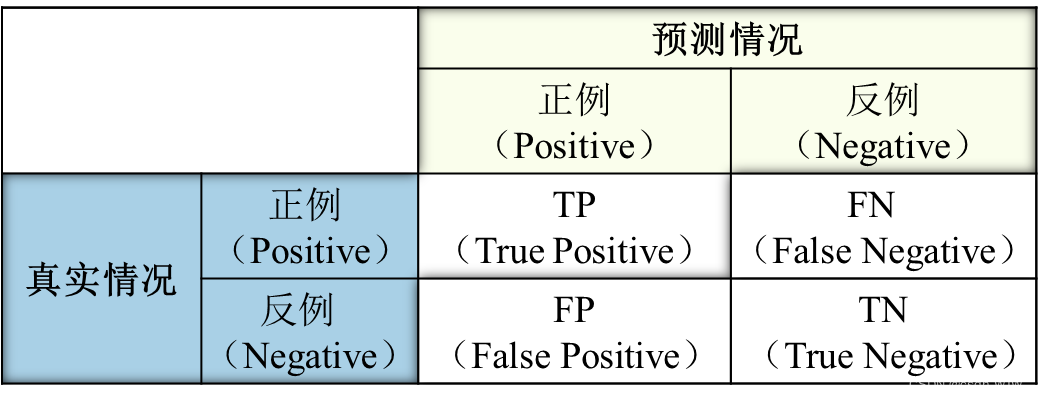
7、查准率(precision):检索出来的有多少是用户感兴趣的;查全率(recall):用户感兴趣的有多少检索出来;
查准率(precision)和精度(accuracy)有区别,精度:分类正确的样本数占样本总数的比例
8、关于P-R曲线

可以用来比较模型优劣
在进行比较时,若一个学习器的P-R曲线被另一个学习器曲线完全“包住”,则可断言后者的性能优于前者。
以A、C为例,A“包住”C,则A的性能高于C,因为在相同查准率或查全率的条件下都是A优于C,可以做水平线和垂线更直观。
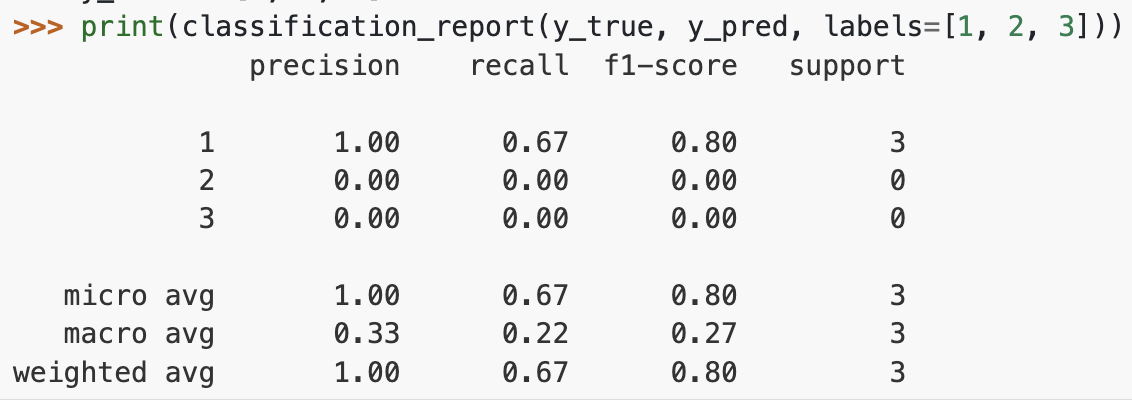
9、macro-F1 和 micro-F1
多分类场景下:
macro 指标是先计算各混淆矩阵对应的 P、R、F1,对这些指标取平均得到 macro-P,macro-R,macro-F1
micro 指标是对各混淆矩阵的 TP、FP、TN、FN 取完平均后,计算 P、R、F1,得到 micro-P、micro-R、micro-F1
附上之前用过的 sklearn.metrics.classification_report()[2],形如:
10、ROC曲线与AUC
AUC值衡量的是模型是否把正例都排在了负例前面。
结合混淆矩阵看
ROC曲线的纵坐标是“真正例率”(TPR),横坐标是“假正例率”(FPR)
取这两个指标做横、纵坐标的原因是:ROC绘制时假设依次每个样本为正例,所以方便计算当前阈值下的真正例率和假正例率。
ROC曲线的绘制过程如下:
- 假设有 m+ 个正例,m- 个负例,对模型输出的预测概率按从高到低排序
- 然后依次将每个样本的预测值作为阈值(即将该样本作为正例),假设前一个坐标为$(x,y)$,若当前为真正例,对应标记点为$(x,y + \frac{1}{m^+})$,若当前为假正例,则对应标记点为$(x,y + \frac{1}{m^-})$
- 将所有点相连即可得到 ROC 曲线
而AUC值就是ROC曲线下的面积,这里[3]有AUC计算过程.
看个例子:
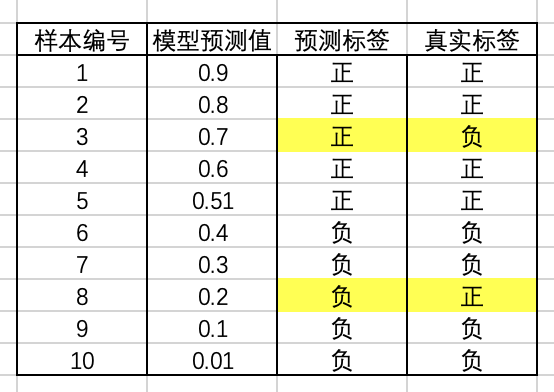
模型有两个预测错误的样本,分别是样本3和样本8,此时AUC=0.8,具体计算过程略过
1 | >> from sklearn.metrics import roc_auc_score |
现在我们直接看最理想的情况下的AUC,帮助理解AUC的含义
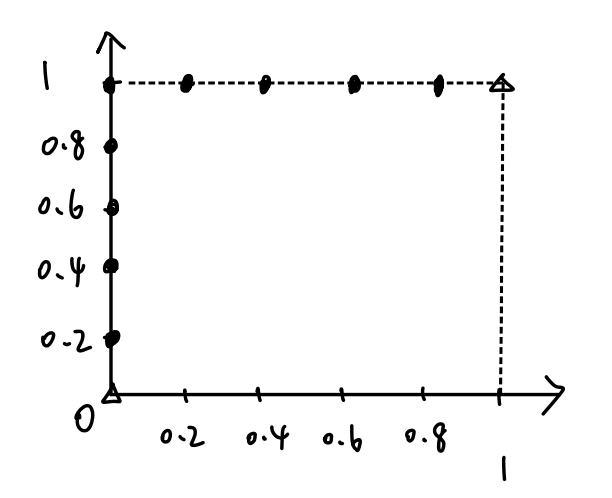
最理想情况下,模型根据预测值给样本排序的结果是:$f(1),f(2),f(4),f(5),f(8) > f(3),f(6),f(7),f(9),f(10)$ ,即把真实标签为正的都排在负的前面了。此时的AUC值一定为1,不信可以描点看看:
- 依次将每个样本的预测值作为阈值(即将该样本作为正例),前五个点一定是$(1,2,4,5,8)$,后五个点一定是$(3,6,7,9,10)$,顺序不重要
- 第一个点,计算TPR和FPR,TPR=1/5=0.2,FPR=0/1=0,坐标$(0.2,0)$
- 第二个点,TPR=2/5=0.4,FPR=0/2=0,坐标$(0.4,0)$
- 第三个点,TPR=3/5=0.6,FPR=0/3=0,坐标$(0.6,0)$
- 第四个点,TPR=4/5=0.8,FPR=0/4=0,坐标$(0.8,0)$
- 第五个点,TPR=5/5=1,FPR=0/5=0,坐标$(1,0)$
- 第六个点,TPR=5/5=1,FPR=1/5=0.2,坐标$(1,0.2)$
- 第七个点,TPR=5/5=1,FPR=2/5=0.4,坐标$(1,0.4)$
- 第八个点,TPR=5/5=1,FPR=3/5=0.6,坐标$(1,0.6)$
- 第九个点,TPR=5/5=1,FPR=4/5=0.8,坐标$(1,0.8)$
- 第十个点,TPR=5/5=1,FPR=5/5=1,坐标,坐标$(1,1)$
- 依次描点作图,顺次连接起来,围住了整个$1 \times 1$的矩形面积,AUC=1
- 再看这句话应该能理解了 “AUC值衡量的是模型是否把正例都排在了负例前面” 。
参考
[1]NFL定理的理解:https://zhuanlan.zhihu.com/p/11312671
[3]AUC计算过程 https://www.scholat.com/teamwork/teamwork/showPostMessage.html?id=9229